The two hard problems we hit, and the architecture that came out of it.
Hey folks,
Most QSR operators don't need another forecasting model. They need to know why last Tuesday was 20% down and what to do about next Tuesday. Those are different problems, and they call for very different software.
That's the realization that led us to rebuild Tactix around a multi-agent architecture. For context: Tactix is an AI platform for restaurant operators. The customers are the people running franchise stores and small QSR groups. The job-to-be-done isn't analytics. It's better daily decisions about labor, inventory, and operations.
We were doing what most restaurant analytics platforms do.
Solid forecasts.
Anomaly detection.
Dashboards full of charts.
The data was right, the numbers were accurate, but operators still couldn't act on most of it.
So how did we solve this, with Agentic AI?
The strategic call we made (trading determinism for explainability), the architecture we ended up with (three sequential agents plus a conversational layer), and the two hard problems we hit on the way: scaffolding a data pipeline that agents can actually consume, and getting agents to communicate without losing the plot.
If you're building agentic systems on top of operational data, the pattern we landed on probably maps to your problem too. So, here's the whole thing.
What restaurant operators actually do
Walk into a QSR back office and watch what the GM does on a Monday morning. They check yesterday's revenue. Glance at this week's labor schedule. Look at the weather forecast. Remember the school board calendar (because school is out next week and that always changes lunch traffic). Try to decide whether to call in extra staff for Friday or scale back.
That whole loop is interpretive. Was last Friday slow because of weather, because of a competitor opening down the street, or because of something we did wrong with staffing? An operator who's been at the same store for five years can usually tell. A new GM is guessing.
A traditional ML stack helps with the first half of this. Forecasts give you the number for next Friday. Anomaly detection flags last Friday as unusual. But neither tells you why last Friday was unusual or what to do about next Friday. The connective tissue between the data and the decision is exactly what operators actually pay for, and it's exactly what most platforms don't ship.
The Tradeoff: Determinism for Explainability
When we made the call to move to a multi-agent architecture, we knew what we were giving up. Traditional ML models are a bit more deterministic. Same input, same output, every time (well, not every time, depending on the model -- but definitely more predictable than generative AI). And this usually means that you can write tests against them. You can guarantee SLAs. And most importantly: you can sleep at night.
Agentic systems are quite the opposite, however. The same input on Monday and Tuesday can produce different outputs because the underlying model has temperature, because the tool call ordering varies, because a downstream agent had different context this time.
And that's a real cost.
What we got in exchange was the ability to produce narrative output that operators can actually use. Not "sales were down 20%." Not "anomaly detected." But this:
Sales were down 20% last Friday. Heavy rain was recorded in your area, and historically rainy Fridays at this location have shown 15-25% lower sales. Worth checking whether your labor schedule for this Friday accounts for the rain currently in the forecast.
You can't write that with a forecasting model. You need something that can pull data, reason about correlations, hedge appropriately on causation, and write English. That's what agents are good at. The tradeoff is that you have to invest heavily in evaluation (more on that later) to recover the determinism you gave up.
Three agents in a pipeline
The architecture we landed on is a sequential agent pipeline. Three production agents, each with a specific job, each handing off to the next.
In Anthropic's Building Effective Agents framework, this is what they call a prompt chaining workflow: a workflow where one LLM's output feeds the next, with optional gates between steps. It's deliberately on the workflow side of the workflow-vs-agent line.
We're not letting the system loop autonomously and decide its own next steps. Each step is structured, and each handoff is something we can observe and test. This way, we can infuse a level of determinism into an inherently non-deterministic solution.
And this choice was deliberate. Anthropic's own guidance is to start simple and only add agentic complexity when you have measured value from it. Their architecture guide notes that fully autonomous multi-agent systems can use 10-15x more tokens than single-agent or workflow-based approaches, and they take months longer to ship reliably. We didn't have that runway. A linear pipeline got us to production fast and gave us something we could reason about.
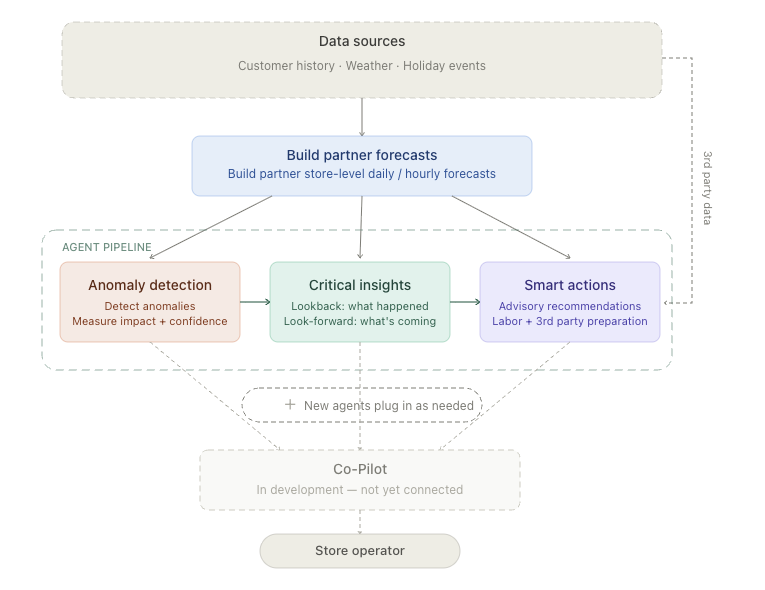
High-level pipeline: anomalies feed insights, insights feed actions. Co-Pilot sits alongside as the conversational layer.
Anomaly Detection runs first. It compares actual store performance to expected performance and flags anything statistically unusual. Its output isn't just "this is an anomaly." It's a structured object with the store ID, the metric, the magnitude, the time window, and a confidence score.
Critical Insights picks up the anomaly output. Its job is to reach for context and explain it. Was there weather? A holiday? An event? It pulls from third-party data sources and produces narrative explanations: "Sales were down 20% on Friday. Heavy rain was recorded." It also handles look-forward: "Heavy rain is forecast for this Friday. Historically, rainy Fridays at your location have shown softer sales."
Smart Actions is the recommendation layer. It takes the insights and turns them into operator-facing guidance: "Consider adjusting your Friday labor schedule given the rain forecast. Plan to act by Thursday morning to give your team time to adjust."
There's a strict tone-of-voice contract that the Smart Actions agent enforces. It never claims causation. It never gives an exact percentage impact. It speaks in ranges, qualified by confidence levels. "Has been associated with" not "caused by."
This is non-negotiable, and it's enforced both in prompts and in evals. And a lot of deliberation and prompt fine-tuning went into this decision.
A fourth agent, the Co-Pilot (we call it Clinton internally), is in development. That's the natural-language interface. It lets an operator ask "How were we doing on rainy Fridays last quarter?" and get an answer that pulls from the same data and tools the other three agents use.
A quick word on the stack
Before going deeper, here's what we're building on, in case it's useful:
FastAPI for the agent runtime and API surface
Google ADK with LiteLLM as the agent framework. ADK gives us the agent primitives (tools, sessions, multi-agent handoffs); LiteLLM lets us swap models when we need to
BigQuery for the data warehouse, with dbt for transformations
Supabase for application state, user data, and pgvector for embedding context
MCP (Model Context Protocol) as the tool layer between agents and data
A PWA as the operator-facing surface
The choices were deliberate but not opinionated.
Although ADK was newer and less battle-tested than other agent frameworks when we picked it, the bet paid off because the multi-agent primitives matched our problem.
MCP was an early bet that's looking better every month as the ecosystem standardizes around it.
Most of our infra is already on GCP, so BigQuery was the easy call given the data volumes and the need for warehouse-scale joins.
Challenges
Challenge #1: scaffolding the data pipeline
The agents are the visible part. The unglamorous part, and the part we spent the most time on, was building a data pipeline that agents can actually consume.
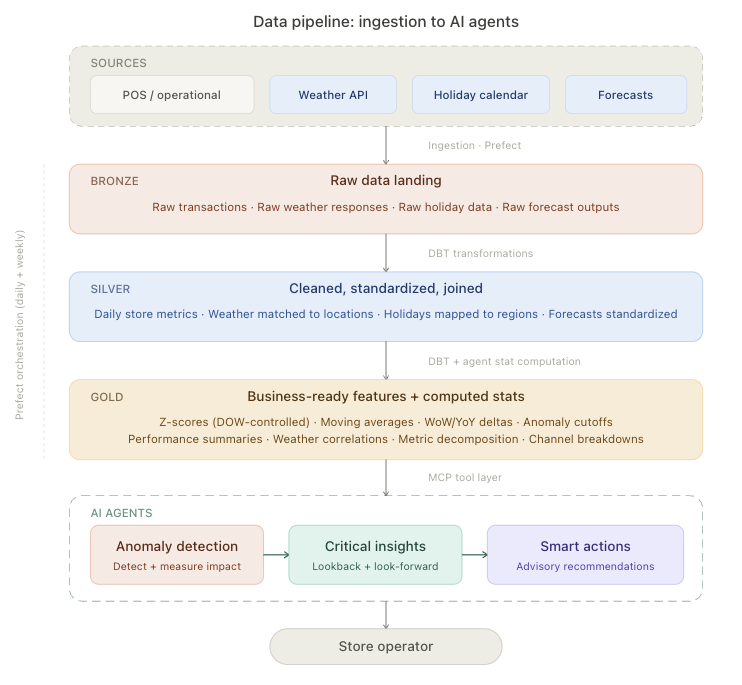
Bronze-to-silver-to-gold medallion architecture in BigQuery. Agents only ever read from gold, and only through tightly-scoped MCP tools.
There's a reason "agents on top of your data" sounds easy and isn't. Agents are bad at raw data. Give an LLM a CSV of point-of-sale transactions and ask it to find patterns and you'll get hallucinations, slow responses, and burned tokens. What agents are good at is reasoning over structured signals. "This metric is 20% below baseline." "The weather was X." "The school district was on break."
So the pipeline has to compute the signals before the agents see them. We built it as a medallion architecture in BigQuery, the bronze-silver-gold pattern that Databricks popularized for lakehouses. Bronze is raw ingestion from POS, weather APIs, and holiday calendars. Silver is cleaned, deduplicated, time-aligned. Gold is computed features, baselines, and correlations. The agents only ever read from gold, and they read through a tool layer rather than running SQL directly.
That tool layer is built on MCP (Model Context Protocol), the open standard Anthropic introduced in late 2024 for connecting LLMs to external data and tools. Each agent has a set of tools it can call:
get_store_performanceget_weather_for_dateget_holiday_contextget_baseline_comparison
The tools are tightly scoped, return structured JSON, and have clear schemas. The agent never sees raw BigQuery rows. It sees pre-computed features, ready to reason about.
Anthropic's guidance on writing tools for agents reinforced something we'd already learned the hard way: tools that just wrap database queries or API endpoints are not the same thing as tools designed for agents. A tool like list_all_stores is technically functional but practically useless.
An agent will burn context iterating through results, so a tool like get_store_with_anomaly_context is purpose-built for the agent's actual job and works far better.
Every new data source we added (weather, holidays, and soon school calendars and airport status) needs bronze-to-silver-to-gold modeling, a tool wrapper, and an eval pass to make sure agents use it correctly. The agents are only as good as the structured signals you feed them.
Challenge #2: getting agents to communicate
Chaining agents together is hard. Not "wire up the API call" hard. The chaining itself is fine. The hard part is keeping the context coherent across the chain.
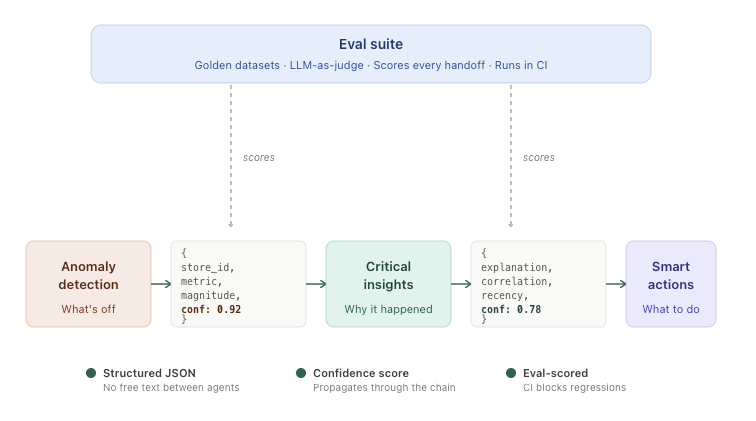
Each agent emits structured output for the next. Confidence scores propagate through the chain. The eval suite scores outputs at every handoff.
So, here's a concrete example.
The Anomaly Detection agent flags a 20% sales drop at a specific store last Friday. It hands the structured anomaly to Critical Insights. Critical Insights checks weather, sees rain, checks holidays, sees nothing relevant, and produces an explanation. So far so good.
Then Smart Actions gets the explanation and has to write a recommendation. Easy, right? Pull the rain context, write something like "expect softer sales this Friday." Except. What if the operator already knows about the rain because Smart Actions wrote about it last week? What if the rain is forecast but mild and the historical correlation at this specific store is weak? What if the agent has to decide between "rain risk" and "school break" because both are happening this Friday and they pull in different directions?
Each handoff is a place the system can lose the plot. We deal with this in three ways.
Strict structured handoffs. Agents never pass free-text to each other. Every agent emits a structured output (JSON with specific fields) that the next agent consumes. The narrative is generated last, by Smart Actions, after the structured reasoning is done.
Confidence scoring. Each agent attaches a confidence score to its output, computed from the underlying data: sample size, historical consistency, signal-to-noise. Downstream agents use confidence to decide how assertively to write. Low confidence means hedged language. High confidence means direct recommendations.
An evaluation suite that runs in CI. This one is the highest-leverage thing we've built. Every quality issue we hit, every customer-reported false positive, every weird agent behavior, gets turned into a test case. Golden datasets per agent. LLM-as-judge to score outputs against expected behavior, the technique introduced by Zheng et al. in 2023 and now widely used for production LLM evaluation. The eval suite runs in CI and blocks merges that regress quality.
The structure looks like this. For each agent we have a curated set of inputs (a real anomaly, a real day's data, a real customer question). For each input we have an expected output shape and an expected reasoning trace. When a PR runs, the agent processes the inputs, the LLM-as-judge scores the outputs across multiple dimensions (accuracy, hedging language, tone, structure), and the PR is blocked if quality drops below a configured threshold. New customer feedback becomes new test cases. The dataset compounds.
The eval suite is the closest thing we have to recovering the determinism we traded away. We can't promise the agents will produce identical output every run. We can promise that on a curated set of representative cases, they hit a quality bar we've calibrated. Anthropic's tools-for-agents post puts the same idea well: tools, and by extension agentic systems, are "a contract between deterministic systems and non-deterministic agents." Eval suites are how you write and enforce that contract. That's what makes the system shippable.
What's coming
The Co-Pilot agent (Clinton) is the next big build. It's the conversational layer that ties the other three agents together. Operators ask questions in plain English and get answers grounded in the same data and tools the rest of the system uses. Document upload (so a manager can leave end-of-day notes for the next shift) and labor report ingestion are the launch features. Embeddings and pgvector handle the unstructured content; structured queries go through the same MCP tool layer everything else uses.
Beyond that, the roadmap is mostly about expanding the structured signal set. School calendars next. Airport disruption data after that. Local events and concerts after that. Each new data source goes through the same bronze-to-gold pipeline, gets a tool wrapper, gets eval coverage, then gets handed to the agents. That sequence is non-negotiable.
The reason it's non-negotiable is that we tried to skip steps once. We added a data source that didn't have eval coverage and shipped agents that referenced it. Within two weeks we had a customer report a misattribution: an agent had blamed a sales drop on a holiday that didn't actually affect that store's market. The fix took a day. The trust hit took longer to recover. The eval suite isn't slowing us down. It's the only reason we can ship at the speed we ship.
Takeaways
A few things we'd tell our past selves about building agent platforms on operational data.
The agents aren't the work. They're the visible part, and they're maybe 20% of the actual engineering. The other 80% is the pipeline, the tools, and the evaluation harness. Plan accordingly.
Pre-compute everything you can. Agents reason well over structured signals and badly over raw data. Spending engineering effort on feature engineering (baselines, correlations, deviations) pays off many times over in agent quality.
Tool layer over query layer. Don't let agents run SQL. Build an MCP-style tool layer with tight schemas, narrow scopes, and structured returns. The agents will be faster, cheaper, and dramatically more accurate.
Tone-of-voice is a contract. When the output is a recommendation that operators act on, the language matters more than the math. We have explicit rules: never claim causation, always speak in ranges, hedge by confidence. These are enforced in prompts and in evals.
Evaluation is what makes agents shippable. It's not a nice-to-have. It's how you recover the determinism you traded away when you moved off traditional ML. Treat the eval suite as a P0 engineering investment, not as something you'll get to later.
Sequential beats orchestrated, for now. A linear pipeline of agents (each doing one thing well, handing structured output to the next) is more debuggable, more testable, and more shippable than a single big "do-everything" agent. We may move to richer orchestration later. We're glad we didn't start there.
If you're working on something similar, we'd love to hear what you've run into. Reach out.
Further reading
The patterns and references that informed how we think about this:
Anthropic, Building Effective Agents. the canonical taxonomy of agentic workflow patterns. Our sequential pipeline maps to their "prompt chaining" pattern. If you read one thing on agent architecture, read this.
Anthropic, Building Effective AI Agents: Architecture Patterns and Implementation Frameworks. the deeper architecture guide, including the token-cost numbers on multi-agent vs single-agent systems.
Anthropic, Writing Tools for AI Agents. why agent-first tool design matters, and the framing of tools as "a contract between deterministic systems and non-deterministic agents."
Anthropic, Code Execution with MCP. recent piece on token efficiency with MCP servers. Relevant if you're hitting context limits as your tool count grows.
Databricks, What is the Medallion Lakehouse Architecture?. the original framing of bronze-silver-gold layering. We use this pattern in BigQuery, but the design principles are platform-agnostic.
Model Context Protocol, Specification. the protocol spec itself. Worth reading if you're building or consuming MCP servers.
Zheng et al. (2023), Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. the foundational paper on LLM-as-judge evaluation.
Comet, LLM-as-a-Judge: How to Build Reliable, Scalable Evaluation. practical guide on layering deterministic and LLM-based evals, which informed how we structured ours.
Until next time, Amit.